What is Bill Of Materials, its types, and uses? All you need to know.
A Bill Of Materials is the heart of any manufacturing line. Let’s take a look at everything about and around them.
Creating a bill of materials is the first step for getting things into production. If you don’t have the raw materials, levels, or resources at your fingertips, tracking profits and proper communication on the shop floor becomes a roadblock.
If you’re new to manufacturing or have confusions around bill of materials, what it is exactly, why it’s used, the different types of BOMs, this blog will help you understand many such concepts and some more about bill of materials.
Bill of materials or BOM is a well known and widely used document in manufacturing and supply chain management.
1. Bill of materials basics
1.1 What is a bill of materials?
In simple words, a bill of materials is a recipe for manufacturing an item. Think of a recipe for your favorite food, it could be tomato soup or a salad. To make the food item ready to eat, you need a list of ingredients and instructions to be performed on the ingredients before it’s ready to eat.
Similarly, a bill of materials (BOM) contains the list and quantities of all the raw materials, subassemblies, item types, steps, and any other relevant information required to reach the finished product. BOMs are hierarchical in nature, meaning there can be multiple levels, more on that later. In the manufacturing cycle, BOMs are like blueprints to your finished products and hence the most important document in any manufacturing or material requirements planning (MRP) cycle.
BOMs are also a means of communication between the customer, manufacturing manager, and shop floor workers indicating the requirements. A BOM can be created for products regularly in stock (make to stock), made when required (make to order), or made with special specifications when required (engineer to order). Regardless of the manufacturing method, BOMs are used everywhere.
1.2 Why is a bill of materials important?
This is similar to a question like “Why do you need a recipe to cook food?”. Of course, you could cook food even without a recipe. But would it be good? Have the right amount of salt? Would you put salt if you’re cooking a dessert? Well, that was a trick question, you need a little bit of salt if you’re baking cakes. But coming to the point, without a BOM you don’t have any standard document to refer to when manufacturing items. The whole manufacturing cycle starts with a BOM.
1.3 Benefits of having a BOM
Having a BOM eliminates doubt from the factory floor and everyone is on the same page. It also has the following benefits:
- Calculate total costs of the manufacturing a product
- Plan for raw materials, workstations, and employees
- Maintain consistent standards for a product across the factory
Now that we’ve established the importance of a BOM, let’s cover some more topics around it.
2. Different types of BOMs
While a BOM is a standard document, there are a few different types applicable to different scenarios. The differences come due to factors like differences in input materials, the nature of the final product to be manufactured, etc.
2.1 Single level BOM or simple BOM
Just the way it sounds, a single level BOM contains only one level of raw materials which will be directly used to manufacture the final product. It is used in production lines where the inputs are already processed raw materials/subassemblies or the manufactured item is simpler i.e., not composed of multiple groups of units. For example, you weave yarn, stitch, and cut it to create towels—this requires only a single level BOM.
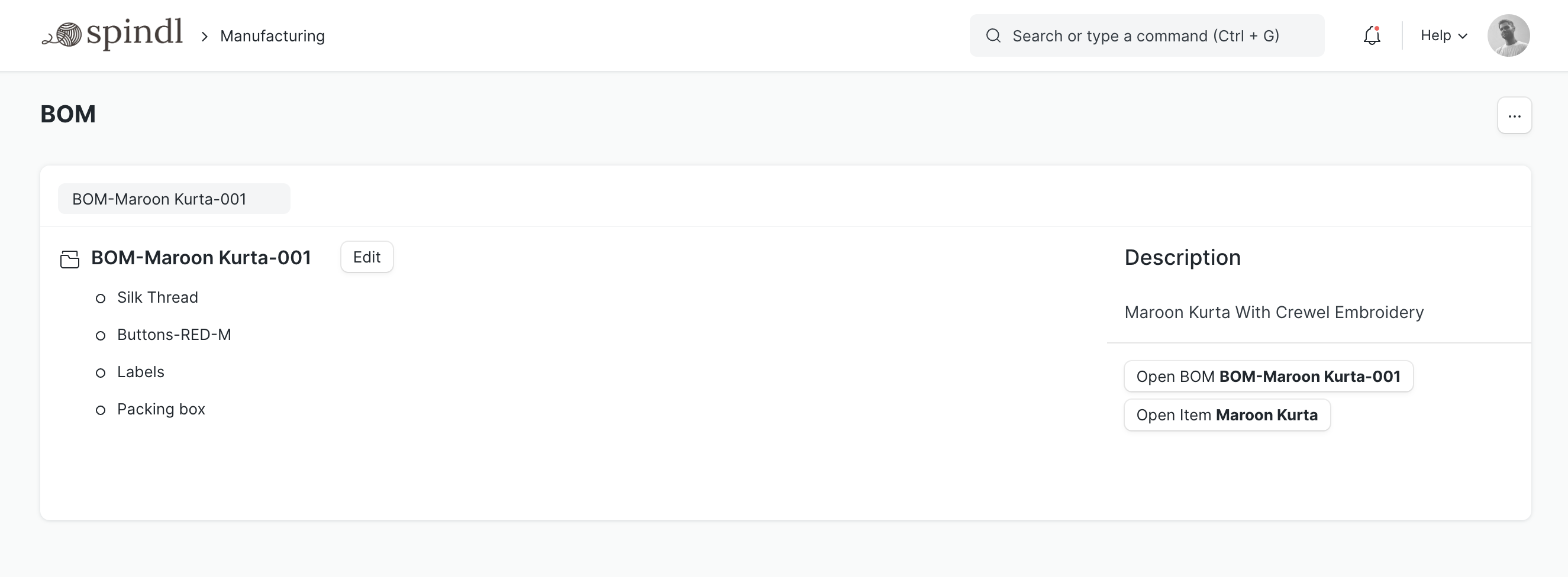
2.2 Configurable BOM
Generally, it’s a good practice to not edit BOMs once used to manufacture an item. But in some industries, different parts may be used with different batches of products. Examples of such industries include servers, PCs, cars and other automobiles, smartphones with different hardware and software based on regions, etc.
Such industries need a lot of flexibility in the way they configure their BOMs. Items may be added, removed, or replaced frequently.
2.3 Multilevel BOM
Remember I said BOMs are hierarchical in nature? This brings us to a concept called multilevel BOMs. Manufacturing more complex products involves creating the sub-assemblies before combining them to piece the finished product. Consider you’re manufacturing a refrigerator for example. After sourcing the raw materials, the subassemblies will be created first. In this case, the raw materials could be biometal, fuse, timer, cooling coil, condenser, pipes, and so on. The subassemblies like the compressor unit and power unit themselves will have their own BOMs and manufacturing process.
This means the refrigerator’s BOM will consist of:
- BOMs of subassemblies (like compressor unit) as raw materials
- These subassemblies could also contain subassemblies of their own (compressor)
- The subassembly parent-child nesting could go on depending on the components and complexity of your product
- ...And possibly some other direct raw materials.
This is known as a multilevel BOM or indented BOM. There is a top-down, parent-child relationship between the different hierarchies in a multilevel BOM.
Here’s a visual representation of a multilevel BOM in ERPNext:
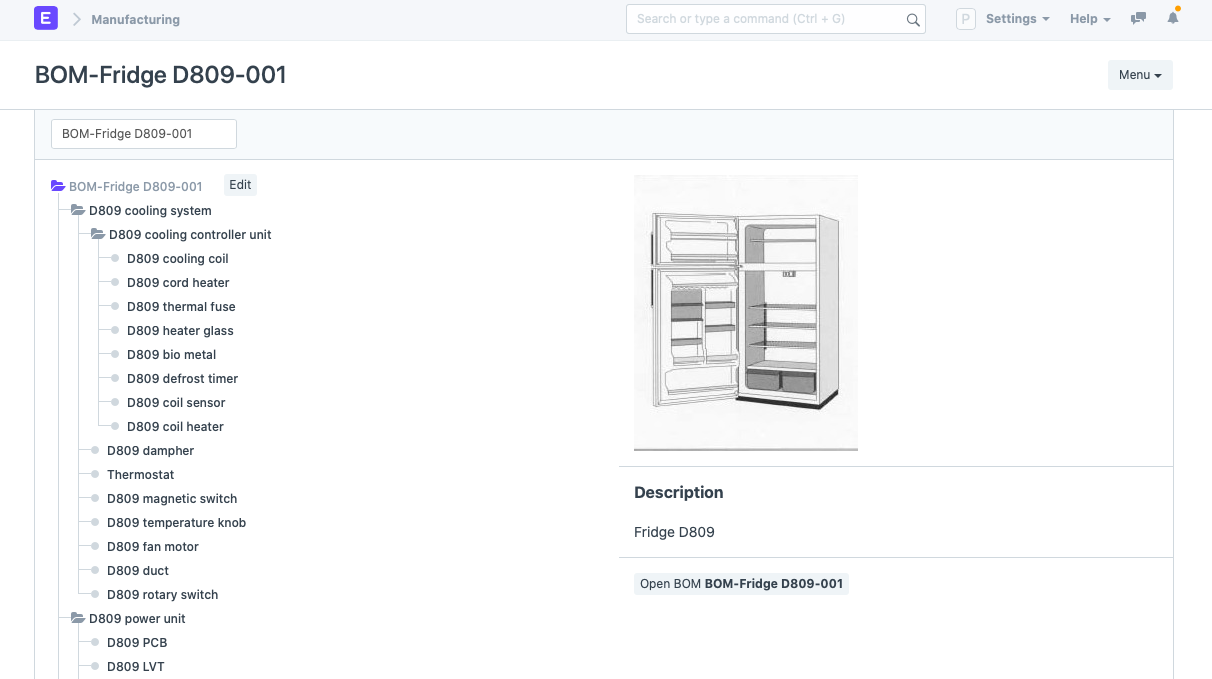
As you can see, the cooling unit is a subassembly that contains a cooling controller unit and other components. Similarly, there are other sub-assemblies for the power unit, gas unit, etc.
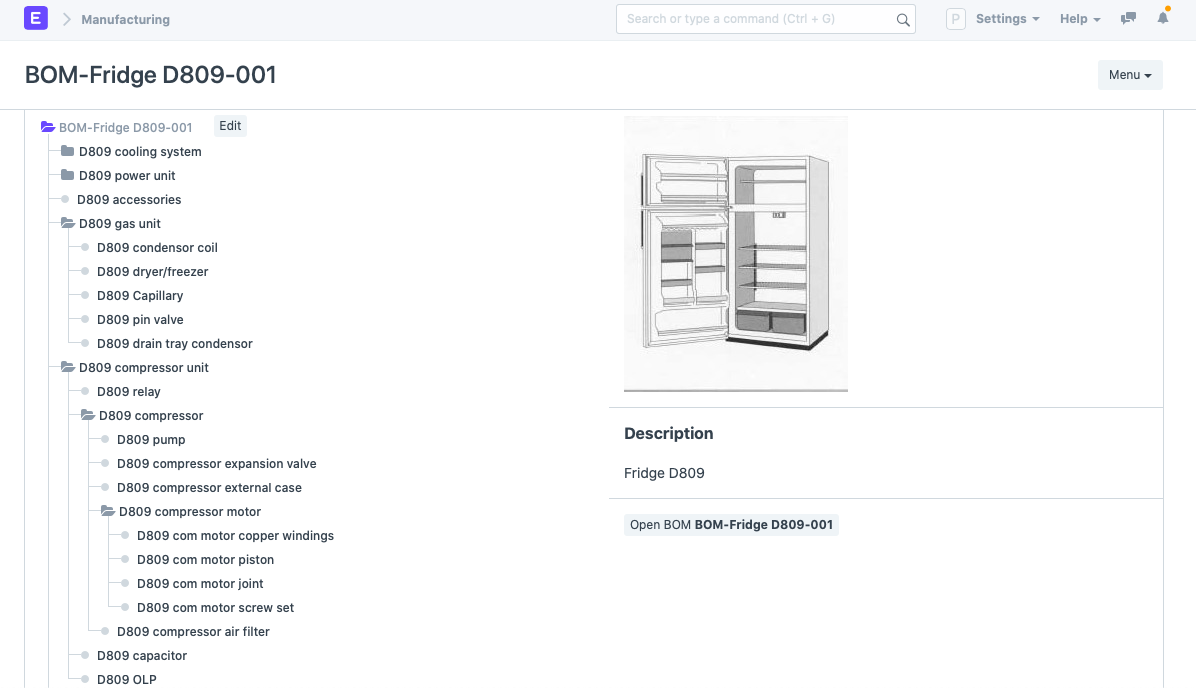
Consider a more nested unit in the following image, the compressor. You can see that the compressor unit consists of the compressor and some components, then the compressor consists of the compressor motor. On a broader scale, this may very well be a simpler example, but in ERPNext you can handle BOMs of varying complexity and levels.
2.4 Software bill of materials
A software BOM is simply a list of packages or components in a software package. It’s similar to a regular bill of materials with the exception that the raw materials or subassemblies in a software BOM are software components required to deliver the final solution. Software solution providers may combine both open source and licensed products as parts to the end solution. Although BOMs are more prevalent in the supply chain and manufacturing industry, getting a software BOM from the supplier with all relevant software versions and details helps ensure that the correct solution is delivered with the latest version. Read more on Wikipedia.
3. BOM operations and costing
3.1 With or without operations?
Whether or not your BOM will have operations depends on the type of manufacturing process your company does. Here, by ‘operations’ I mean any steps or actions that you need to take to process a raw material or subassembly further in the manufacturing process. For example, if you’re manufacturing electric wires, your operations will look similar to:
- Melt raw copper
- Draw it out to wires/strands of copper
- Group wires into a set of wires
- Coat the group of wires with plastic insulation
Such ‘operations’ are not required if your company is only into simpler assembly line operations. For example, gluing furniture parts together. But on elaborate assembly lines with multiple operations happening at different areas (workstations), it’s important to record and keep track of the operations performed to reach the finished product.
Think of making a sandwich by simply putting a slice of cheese between two bread slices, you don’t really need instructions do you? But if you’re making a grilled sandwich with cheese, butter, tomato, lettuce, dipping sauces, etc. you definitely need instructions to get it right.
3.2 BOM costing
Apart from being the blueprint for items, BOM is also vital for calculating the final costs of manufacturing goods. Depending on your process, there can be multiple costs involved and hence a software is usually the recommended way to go. Let’s take a look at the various costs involved in manufacturing including the raw materials:
- Raw materials
- Electricity
- Fuel
- Subcontracting (if applicable)
- Workstation rent
- Employee wages
Here’s what BOM costing looks like in ERPNext. The operating costs are calculated automatically from the operations and workstations.
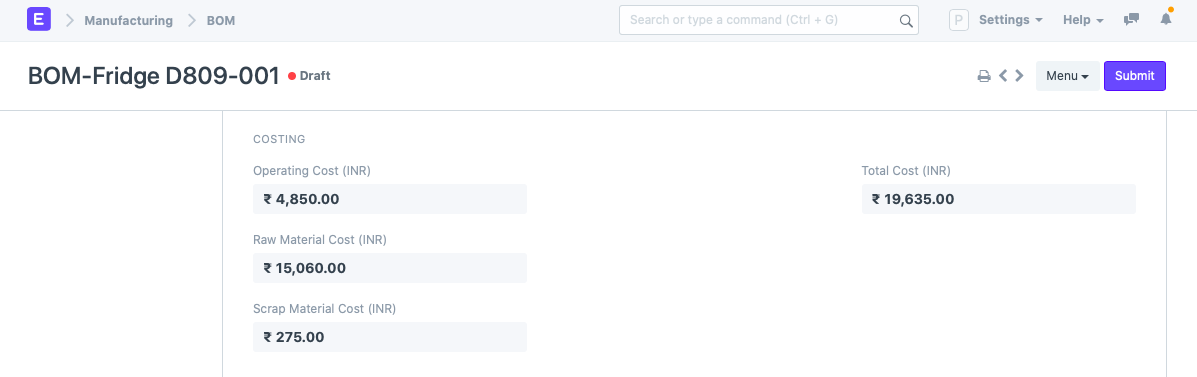
3.3 BOM comparison
When there are multiple iterations (and BOMs) of the same item, the raw materials change between them. Over multiple iterations, it’s important to keep track of what changed to avoid any confusion before starting on the manufacturing order. Comparing two BOMs side by side helps with this problem.
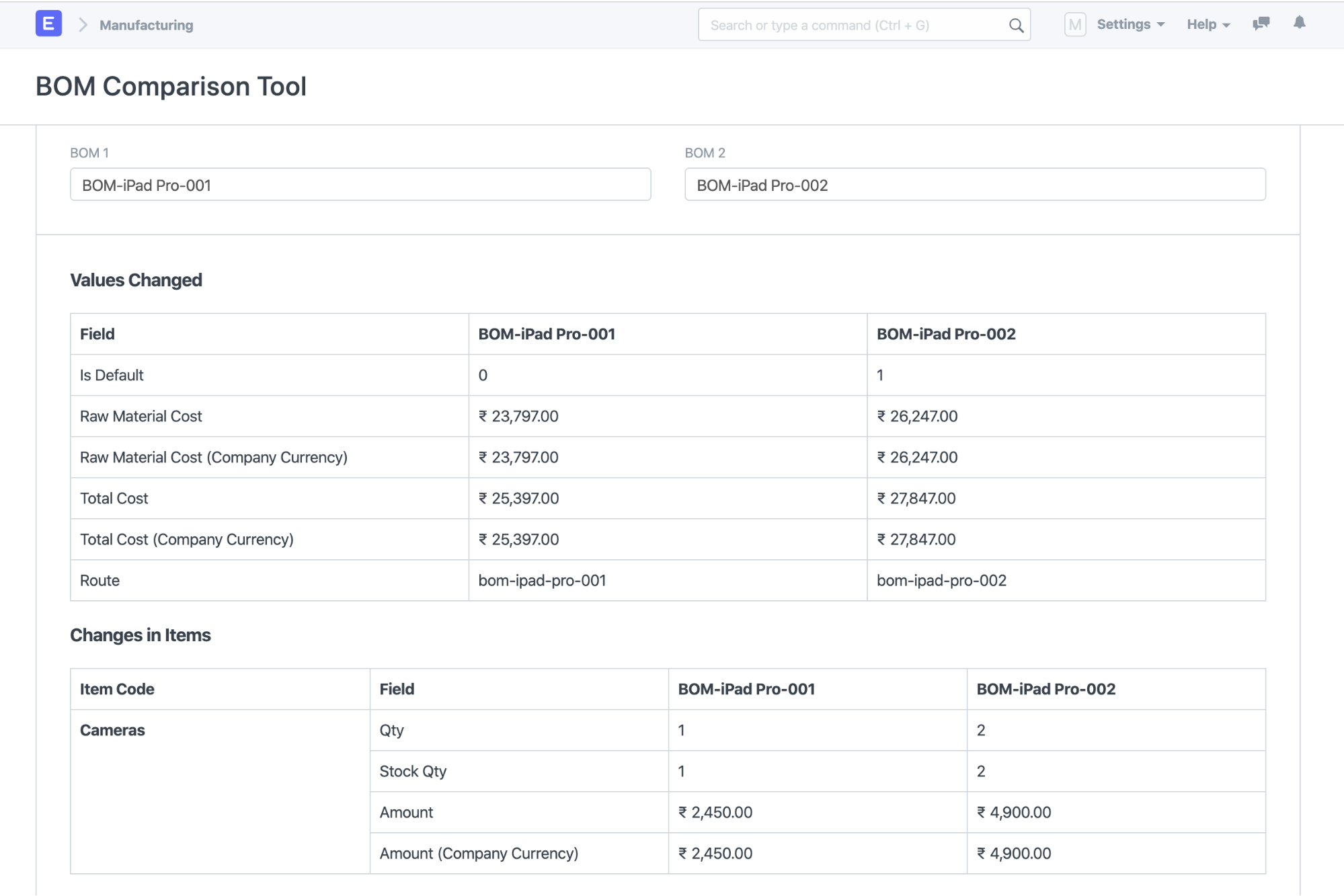
In the example above, the older BOM is 001 on the left and the newer one is 002 on the right. As you can see, the prices have changed and the changed raw materials are shown below it.
4. Inventory in BOM
4.1 Finding BOMs with items
What if you want to find the BOMs in which a particular item or items are being used? Sure you could whip up some macros or link spreadsheets to keep track. But this becomes difficult using spreadsheets when your manufacturing operations scale. Using software for BOM and manufacturing makes things much easier. For example:
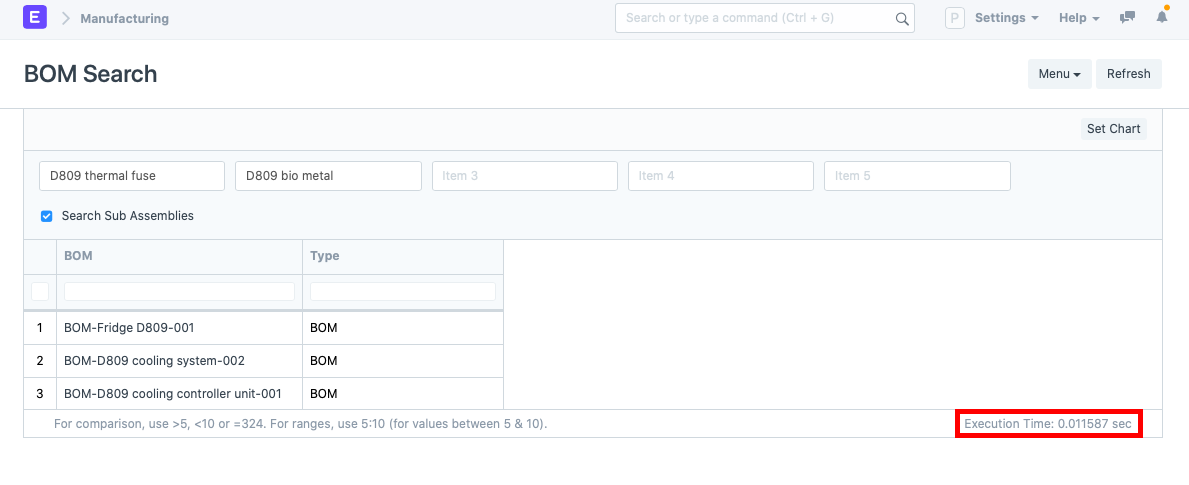
Note the execution time at the bottom right. It took less than a second to search within the finished product and subassembly BOMs. But a disclaimer is due, when your database has multiple thousands of BOMs, this may become slower but beats searching spreadsheets or navigating complex ERP UI any day.
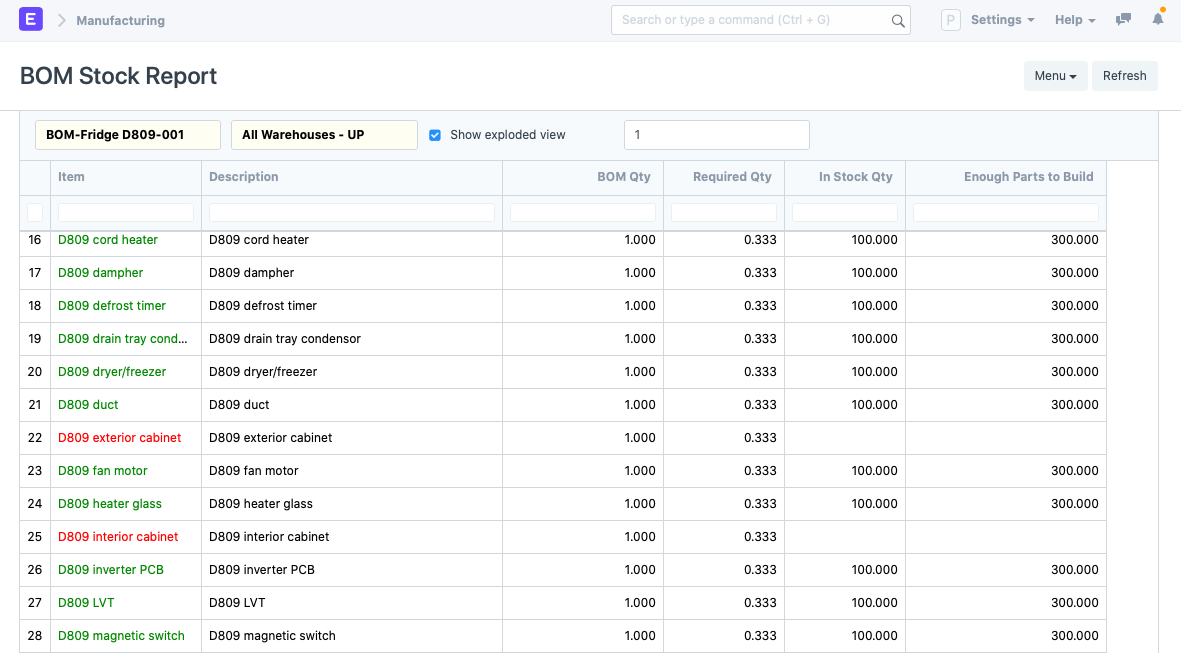
4.2 Finding inventory levels for BOM items
Once you start manufacturing more items, things only get more complex. After a few weeks, you’ll ask questions like “How to find the inventory levels in the warehouses for the BOMs?”. You can whip up charts with spreadsheets or use some advanced search or scripts. In ERPNext, you simply have to open a report and the rows are color graded. Green means the stock is sufficient and red means insufficient stock for manufacturing the product of the selected BOM.
5. Creating BOMs
5.1 How to make a bill of materials
5.1 How to make a bill of materials
Before creating a BOM, let’s take a look at what should be included a BOM.
- Item name: Name of the finished product you’re manufacturing.
- Quantity: The number of items that can be manufactured using the BOM.
- Materials: The raw materials and subassemblies required to manufacture the finished product.
- Cost: The total cost of all the materials, labor, workspace, electricity, fuel, etc.
- Operations/Actions: Any additional steps or transformations that need to be performed on the raw materials.
- Requisition method: Details about whether the raw materials and subassemblies are procured with purchases or manufactured.
These are basic details. Your BOM may include additional fields or notes depending on the complexity of your manufacturing line.
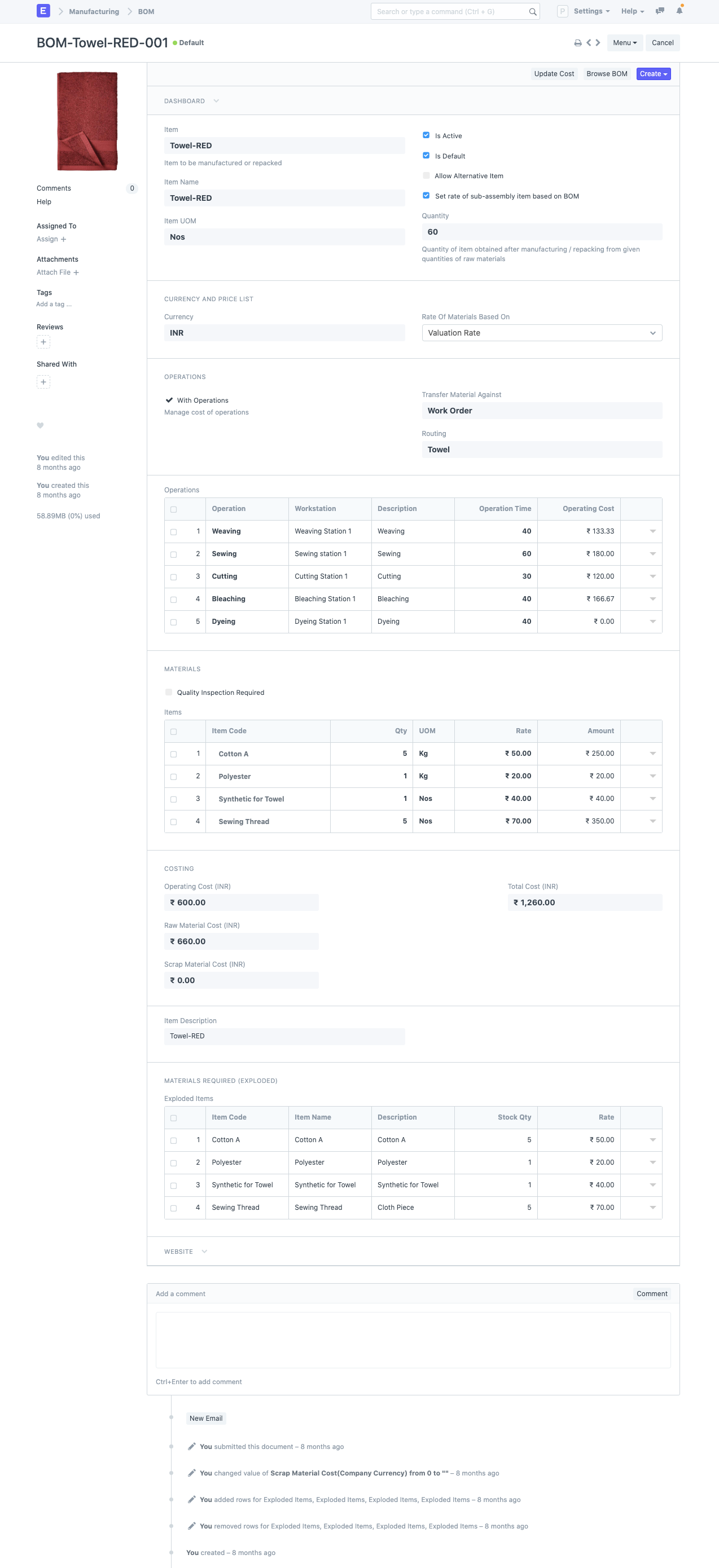
5.2 Bill of materials example
Here’s a simple example of what a BOM looks like in ERPNext:
{kind=link}
Here is an example PDF of a BOM generated in ERPNext that you can print or email.
You can also upload the PDF file to your ERPNext account like I did above and share the file link with third parties directly. How cool is that?
5.3 Bill of materials template using spreadsheets
If you’re a smaller company, it may not be practical for you to purchase an MRP software.
Here are 48 BOM templates by templatelab. You can download them for free according to your needs. Remember to experiment with different templates and choose one to keep everything consistent.
5.4 BOM using ERPNext
Using an ERP system like ERPNext to create and manage BOMs is much easier and faster. The structure is created by default, all the configuration options are present, items and operations can be fetched from records. The costing is done automatically once you enter the item costs and operation costs for different areas like electricity and fuel.
Here is a slightly dated video on creating a BOM in ERPNext.
You can find the newer features and detailed steps on creating a BOM in ERPNext in the documentation.
6. What to do after creating BOM?
Like we saw earlier, a BOM is only the first part. In order to maintain a medium to large successful manufacturing process, you should be recording further steps and also some steps before creating a BOM.
6.1 Before a BOM
Typically, a BOM is the first transaction step in a manufacturing line, but 2 actions happen before a BOM in the overall cycle.
- Receiving a customer order: Once a customer order has been confirmed, you know the exact quantities of finished goods to be delivered to the customer. Particularly useful in make to order but also helps planning even if you do make to stock.
- Creating a production plan (resource planning for manufacturing): Once you have one or multiple customer orders, it’s time to plan for manufacturing. This is where a ‘production plan’ comes into the picture. After receiving a customer order, you have to figure out things like:
- Calculating the required raw materials
- Which workstations to engage
- When can you complete this order when there are other orders already in the pipeline
In such situations, an MRP or ERP software comes very handy since it calculates everything for you. It’s as simple as fetching the customer order into your production plan
6.2 After a BOM
After creating a BOM, the actions that happen next are:
- Creating a manufacturing order or work order
- Processing the raw materials (any operations to transform the raw materials)
- Assigning job cards to different employees
- Shifting materials between bins or warehouses and workstations
These topics are out of the current scope and deserve an article of their own.
Anyway, here is an overview of a typical manufacturing flow as seen in ERPNext:

6.3 Choosing software for BOM
A smaller and less complex manufacturing process could very well be handled with spreadsheets. But tracking raw materials, subassemblies, and manufactured products becomes increasingly difficult when the items you produce increases. After a point, maintaining different spreadsheets and versions becomes friction in communication even if you use online spreadsheet solutions. It’s recommended to switch to a software solution when spreadsheets are visibly reducing your shop floor’s efficiency.
With ERPNext, you can manage your complete manufacturing process, inventory, HR, and much more. The best part is that its open source, so you can experiment for a few weeks yourself if you’re unsure before you seek any professional help. Also, you can import your existing data using features like Data Import.
7. FAQs
Q. Should you edit a BOM?
A: Usually no, this isn’t standard practice. Each BOM once used should be uniquely identifiable with the item manufactured. But you could if your industry requires the BOM to be changing frequently (configurable BOM).
Q. What about BOMs for different types of the same item? (item variants)
A: Sometimes the regular item is unavailable. In such cases, you can use a replacement item with similar properties. For example, using alloy steel instead of carbon steel. ERPNext has a feature called the BOM template to manage variant BOMs easily.
Q. What is BOM implosion and BOM explosion?
A: Since BOMs are hierarchical in nature and contain subassemblies the individual raw materials can be grouped together or separated. An explosion shows a fully expanded view of all the subassemblies and items down to the lowest level. A BOM implosion is a collapsed view that shows the links between subassemblies and the finished product.
Conclusion
As we explored, a BOM is the backbone of any manufacturing process. We saw what a BOM is, why it’s important, what are the different types of BOM, and some other actions surrounding a BOM that exist in a manufacturing line. Then we briefly covered some concepts like BOM comparison, exploring BOMs, saw some examples, and covered some FAQs. Remember, whatever you’re manufacturing, create the BOM first.
I hope you found this BOM guide useful. Did it help you understand the basic concepts around a BOM? Ok this is the last time I'll say BOM in this blog. BOM. Share your thoughts below.
For a monthly digest of such blogs and more updates, subscribe to our newsletter
References
Prasad Ramesh
Marketing at Frappe.
@Graeme, thanks for pointing this out. Updated the images, 4.1 now shows the BOM search feature.
I think you've got a wrong image in section 4.1. The image is for BOM Stock report, but the text is for finding which BOMs a part is used in. The image is more suited for the next section (4.2).
for multilevel BOM ,say six levels,how to do MRP if the sub assemblies at various levels are also available in stores.Do we have any method by which system will use available sub assemblies and throw report of requirement of only for balance raw material ...... Without this feature how to plan material?..?.for such multilevel product.
Very informative, thank you ??